The global data landscape has shifted fundamentally in 2026. Enterprises no longer view Data Warehouse Consulting as a task for historical reporting. Instead, they see it as the primary engine for Generative AI (GenAI). According to recent 2026 industry forecasts, nearly 30% of enterprises now automate half of their operations using Large Language Models (LLMs). This transformation requires more than just "saving" data. It requires a specialized architecture that turns raw logs into "AI-ready" assets.
Modern Data Warehouse Consulting Services now focus on a specific goal: bridging the gap between static storage and dynamic reasoning. This details the technical roadmap for preparing your warehouse for the era of GenAI and Agentic AI.
The New Architecture of Intelligence
Traditional data warehouses were built for humans to read dashboards. In 2026, the primary consumer of data is the AI agent. This shift changes every layer of the technical stack.
1. The Rise of the Data Lakehouse
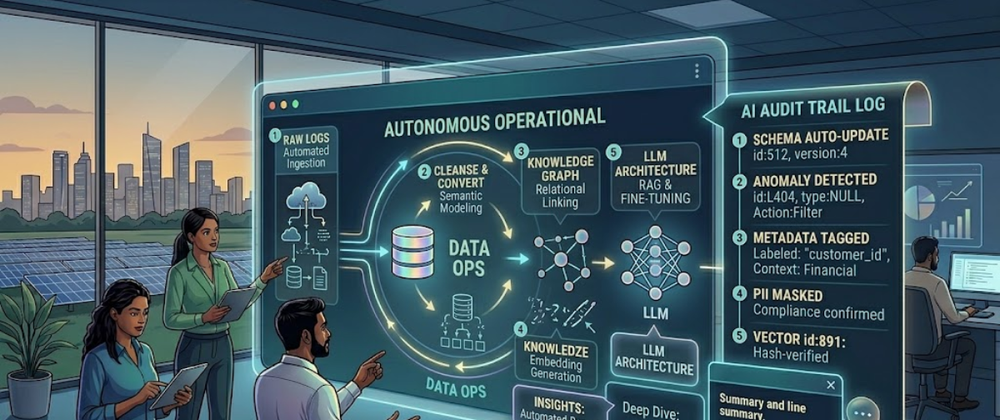
Data warehouses are no longer just for structured tables. GenAI requires "unstructured" context—emails, PDFs, and raw system logs. Data Warehouse Consulting teams now implement "Lakehouse" architectures. This model combines the structure of a warehouse with the massive storage of a data lake. It allows LLMs to query SQL data and read raw text files in a single environment.
2. Vector Integration: The AI's Memory
Standard SQL databases cannot "understand" meaning. They only match text strings. To support GenAI, modern warehouses now include Vector Search.
Embeddings: We convert raw text into numerical arrays called vectors.
Semantic Search: This allows an AI to find "related" concepts even if the exact keywords do not match.
Hybrid Search: Systems in 2026 use a "Hybrid" approach. They combine vector similarity with traditional metadata filtering to ensure 99% precision.
Phase 1: Data Cleansing for LLM Training
GenAI is only as good as the data it consumes. Statistics from 2025 and 2026 show that 35% of AI users cite "inaccurate output" as their top concern. Most of these errors stem from poor data quality in the warehouse.
1. Eliminating Noise and Bias
Data Warehouse Consulting Services prioritize "Data Distillation." This involves removing "boilerplate" text, duplicate logs, and low-quality entries.
- Deduplication: Repeated data confuses the "weights" of an LLM during fine-tuning.
- Bias Mitigation: By 2026, 70% of LLM applications must include transparency features. This requires scrubbing the warehouse of biased historical labels before the AI ever sees them.
2. The Contextual Enrichment Layer
Raw logs lack meaning without metadata. For example, a temperature log of "100" means nothing alone. It requires context: Is it Celsius? Is it an engine or a room?
- Metadata Tagging: We use small, specialized AI models to "auto-tag" raw data with business context.
- Lineage Tracking: You must track where a data point came from. This ensures the LLM can "cite its sources," which is critical for legal and financial compliance.
Phase 2: Building the RAG Pipeline
Most enterprises do not train their own LLMs from scratch. Instead, they use Retrieval-Augmented Generation (RAG). RAG allows a public model (like Gemini or GPT-4) to "look up" private information in your warehouse to answer a question.
1. Technical Requirements for RAG
To make RAG work, your Data Warehouse Consulting partner must build several "Real-Time" components:
- Change Data Capture (CDC): As soon as a customer updates their profile, the vector store must update instantly.
- Context-Aware Chunking: You cannot feed an entire 100-page manual to an AI at once. We must break data into "chunks" that are small enough to process but large enough to maintain meaning.
- Token Optimization: LLMs charge per "token" (parts of words). Efficient warehousing involves "compressing" data so the AI gets the most information for the lowest cost.
2. Agentic RAG: The 2026 Standard
By 2026, we have moved beyond "Simple RAG" to "Agentic RAG."
- Multi-Step Reasoning: The AI agent identifies it needs data from three different tables.
- Tool Use: The agent "calls" the warehouse to run a SQL query, analyzes the result, and then decides if it needs more data.
- Self-Correction: If the warehouse returns a null value, the agent tries a different search strategy automatically.
Phase 3: Governance and Security in the AI Age
Connecting an LLM to your corporate data warehouse introduces massive security risks. Data Warehouse Consulting Services now spend 40% of their time on "AI Guardrails."
1. Preventing Data Leakage
Commercial LLMs often "learn" from the data you send them. If you are not careful, your trade secrets could end up in a competitor's AI response.
- Private Endpoints: We ensure data stays within your virtual private cloud (VPC).
- PII Redaction: Automated pipelines scan every query and "mask" sensitive information (like Soc ial Security numbers) before it reaches the LLM.
2. Role-Based Access for AI
Just because a chatbot is "smart" doesn't mean it should see everything.
Entitlement Mapping: If a junior employee asks the bot about "CEO Salaries," the warehouse must deny that specific data retrieval.
Audit Logging: Every prompt and every retrieved data chunk must be logged. This provides a "clear audit trail" for when things go wrong.
Establishing the "Data-to-AI" Loop
The final step is creating a continuous loop. As the AI interacts with users, it generates "feedback data." This feedback goes back into the warehouse to improve the next generation of models.
Continuous Fine-Tuning
Modern Data Warehouse Consulting includes "Reinforcement Learning from Human Feedback" (RLHF) pipelines. When a user tells the chatbot "That answer was wrong," the system logs the error. Data engineers then use these "Negative Examples" to retrain the RAG retrieval logic. This ensures the system gets smarter every single day.
Challenges: Why Projects Fail
Even with the best tools, many GenAI projects stall. Experts identify three common technical failures:
- - Data Silos: If your CRM data is not in the same "Lakehouse" as your support logs, the AI will give incomplete answers.
- - Poor Chunking: If you cut a sentence in half during the vectoring process, the AI loses the context.
- - Latency Issues: If your warehouse takes 10 seconds to find a vector, the chatbot feels "slow" and "broken" to the end user.
The Future: Zero-ETL and Autonomous Warehouses
As we look toward 2027, the trend is moving toward "Zero-ETL." This means the data warehouse will live "on top" of your operational databases. There will be no more "moving" data. The AI will simply "see" the data wherever it lives. Data Warehouse Consulting Services are currently building the governance layers to make this "Universal Visibility" safe and reliable.
Conclusion
Moving from "Raw Logs" to "LLMs" is the most significant technical challenge of the decade. It requires a complete rethink of how we store, clean, and retrieve information. A modern Data Warehouse Consulting strategy must prioritize semantic search, RAG optimization, and rigorous security.
By 2026, the data warehouse has evolved from a "Cabinet of Records" into a "Brain of the Business." Investing in professional Data Warehouse Consulting Services ensures that your organization is not just "storing" data, but actively "reasoning" with it. The companies that master this pipeline will dominate their industries, turning their raw logs into a permanent, automated competitive advantage. Preparation is the only path to AI success—start building your foundation today.





Top comments (0)